
Studies on computer vision constantly expand the horizons of the possibilities of editing and creating video content, and one of the new innovative tools presented at an international conference on the computer vision in Paris is Omnimotion. Is described in the newspaper “Tracking everything everywhere at once.“Developed by Cornell researchers, this is a powerful optimization tool designed to estimate the movement in video materials. It offers potential for complete transformation of video editing and creating generative content using artificial intelligence. Traditionally, the method of traffic estimation has used one of the two main approaches: tracking rare objects and the use of optical flow. Solve this problem is often limited by the context. in time and space, which leads to the accumulation of errors during long trajectories and inconsistency in estimates.
- Tracking for a long time
- Tracking traffic even through occlusion events
- Ensuring consistency in space and time
Omnimotion is a new optimization method designed to more accurately estimate both dense and long -range traffic in video sequences. Unlike previous algorithms that operated in limited time windows, Omnimotion provides a complete and globally coherent traffic representation. This means that every pixel in the film can now be carefully followed throughout the film, opening the door to new possibilities of exploration and video content. The method proposed in Omnimotion can support complex tasks, such as occlusion tracking and modeling of various combinations of camera and object movement. Tests conducted during research showed that this innovative approach easily exceeds previously existing methods in both quantitative and qualitative terms.

Dig. 1. Omnimotion jointly follows all points in the film in all frames, even through occlusion.
As shown in the above illustration of movement, Omnimotion allows you to estimate the trajectory of full -scale movement for every pixel in every video cage. The rare trajectories of the first plan objects are shown for clarity, but the omnipotence also calculates trajectory of movement for all pixels. This method provides precise, coherent traffic over long distances, even in the case of fast -moving objects, and reliably follows objects even over moments of obstruction, as shown in examples with a dog and a swing.
In Omnimotion, Canonic Tom G is a 3D Atlas containing information about the film. Contains the Fθ coordinates based on the NERF method to determine the correspondence between each canonical 3D coordinate, σ density and color C.
Information about the density help identify surfaces in the frame and determine whether the objects are closed and the color is used to calculate photometric loss for optimization. The canonical 3D volume plays an important role in registering and analyzing traffic dynamics in the stage.
Omnimotion also uses a 3D beetroot, which ensures continuous correspondence of one to one between 3D points in local coordinates and the canonical 3D coordinate system. These bikends ensure the consistency of movement by ensuring that the correspondence between 3D points in various frames comes from the same canonical point.
To represent a complex movement in the real world, the beatings are implemented using reversible neural networks (Inns) that provide expressive and adaptive display capabilities. This method enables ubiquity to accurately capture and track traffic on the framework while maintaining general data consistency.
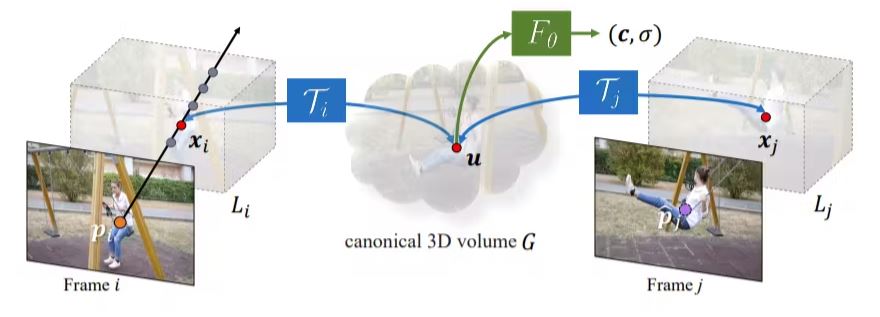
Figure 2. Method review. Omnimotion consists of canonical 3D G volume and 3D battle set
To implement omnimotion, a complex network was created consisting of six layers of Afinical transformation. It is able to calculate the latent code for each frame using a 2-layer network with 256 channels, and the dimension of this code is 128. In addition, the canonical representation is implemented using Gabornet architecture equipped with 3 layers and 512 channels. Pixels coordinates are normalized to the range (-1, 1), and for each frame the local 3D space has been determined. Mounted canonical locations are initiated in the unit sphere. Also compression operations adapted with MIP-WERF 360 They are used for numerical stability during training.
This architecture is trained in every video sequence with Adam Optimizer for 200,000 iterations. Each training set includes 256 pairs selected from 8 pairs of paintings, which gives a total of 1024 matches. It should also be noted that 32 points were selected for each ray using a stratified sampling. This sophisticated architecture is the key to the outstanding Omnimotion performance and solves the complex challenges related to the estimation of video movement.
One of the very useful aspects of Omnimotion is his ability to extract pseudo-depression from the optimized QUASI-3D representation. This provides information about the different depths of various objects on the stage and displays their relative items. Below is an illustration of pseudo-pogene visualization. The nearby objects are marked blue, and distant objects are marked with red, which clearly shows the order of different parts of the stage.

Figure 3. Pseudo-deep visualization
It should be noted that, like many methods of traffic estimation, Omnimotion has its limitations. It does not always cope with very fast and rigid movements, as well as thin structures on the stage. In these special scenarios, couples' correspondence methods may not provide sufficiently reliable fit, which may lead to a lack of accuracy in global traffic calculation. Omnimotion is still evolving to deal with these challenges and contributes to the development of video analysis.
Try the demo version Here. Technical details are available on Girub


















{kind=link}