
Large language models (LLM), such as GPT-4, are considered technological miracles capable of successful opinion of Turing test. But is it really?
Chatgpt took on the great heights in the field of artificial intelligence (AI). It may seem smart, fast and impressive. He skillfully shows visible intelligence, engages in conversations with people, imitates human communication, and even passes exams in case law. However, in some cases it still contains completely false information.
So can Chatgpt pass Turing's test, generating an indistinguishable text and a human reaction?
Two researchers from the University of California in San Diego examined this question and discovered intriguing results. Cameron Jones, which specializes in language, semantics and machine learning, and Benjamin Bergen, a professor of cognitive science, conducted a Turing online test. In this test, participants tried to determine whether the respondent was AI or a man. GPT-3.5 or GPT-4 acted as artificial intelligence.
The experiment included an online test, which included talks between 650 participants and GPT models. Participants were asked to determine who they talked to, man or AI. The experiment used various GPT-3.5 and GPT-4 configurations. Most of the researchers studied a prompt that LLM directed to a specific topic and style of conversation. This hint defined the nature of the agent's interaction and personality and was varied to see how it affected the result.
Each dialogue had a 5-minute time limit and message length below 300 characters. In total, 652 participants took part in the experiment and ended 1810 “Games”. After filtering dubious results, the number of “games” was reduced to 1405.
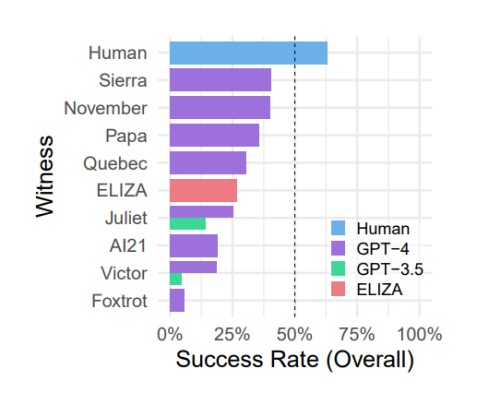
The discoveries revealed that the GPT-4 models managed to deceive participants in 41% of cases, while GPT-3.5 models were only 5–14% of the time. For comparison, the older model Eliza (1966) was recognized as a person in 27% of cases. In addition, an interesting fact was discovered: the participants managed to convince other participants that they are not machines only in 63% of cases.
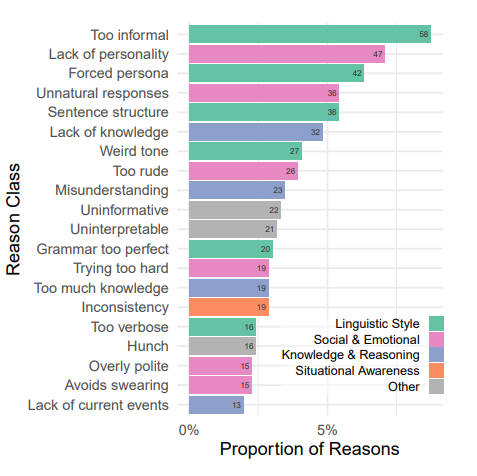
The motives of the participants' decisions were rather an interesting aspect. The reasons why AI was considered AI were as follows. If artificial intelligence seemed too formal or informal, this may cause anxiety. Similarly, the answers that were too difficult or too short, strange tone of conversation or excellent grammar became important factors in determining whether the interlocutor was man or machine. It is also worth noting that the lack of knowledge turned out to be more important than excess. This suggests that AI models should learn. Test participants also showed sensitivity to general answers.
Scientists came to the conclusion that on the basis of this experiment it cannot be stated that the GPT-4 successfully passed Turing's test. Nevertheless, 41% success indicator indicates that the use of AI for fraud becomes more realistic. This is particularly important in situations where human interlocutors are less deserted to communicate with the machine.
AI adept models in imitating human reactions can potentially influence the social and economic effects. Monitoring AI models and identification of factors leading to fraud, as well as developing a softening strategy. However, scientists emphasize that Turing's test remains an important tool for assessing machine dialogue and understanding of human interaction with artificial intelligence.
It is unusual how quickly we have achieved a stage in which technical systems can compete with people in communication. Despite the doubts about the success of the GPT-4 in this test, its results indicate that we are approaching the creation of artificial intelligence that can compete with people in conversations.
Read more about the study Here.







")









{kind=link}