
In the rapidly evolving large language model (LLM) landscape, attention has focused largely on decoder-only architectures. While these models have demonstrated impressive capabilities in a wide range of generation tasks, classic codec architectures such as T5 (text-to-text transfer transformer) remain a popular choice in many real-world applications. Encoder-decoder models often excel in summarization, translation, quality control, and more due to their high inference performance, design flexibility, and richer encoder representation for understanding input data. Nevertheless, the powerful encoder and decoder architecture has not received relative attention.
Today we will revisit this architecture and introduce it T5Gemmaa new collection of LLM codec modules developed by converting pre-trained decoder-only models to a codec architecture using a technique called adaptation. T5Gemma is based on the Gemma 2 framework, which includes customized Gemma 2 2B and 9B models, as well as a set of newly trained T5-sized models (Small, Base, Large and XL). We are excited to make pre-trained and tuned T5Gemma models available to the community to unlock new research and development opportunities.
From the decoder itself to the codec
At T5Gemma we ask the following question: Can we build first-class encoder-decoder models based on pre-trained decoder-only models? We answer this question by examining a technique called model adaptation. The basic idea is to initialize the encoder-decoder model parameters using the weights of an already pre-trained decoder-only model, and then further fine-tune them through UL2- or PrefixLM-based pre-training.
An overview of our approach showing how we initialize a new codec model using parameters from a pre-trained decoder-only model.
This adaptation method is very flexible and allows you to creatively combine model sizes. For example, we can pair a large encoder with a small decoder (e.g. encoder 9B with decoder 2B) to create an “unbalanced” model. This allows us to fine-tune the quality-performance trade-off for specific tasks, such as summarization, where a deep understanding of the input data is more important than the complexity of the generated results.
Towards a better compromise in quality and performance
How does T5Gemma work?
In our experiments, T5Gemma models achieve comparable or better performance than their decoder-only Gemma counterparts, almost dominating the quality inference efficiency frontier in several benchmarks such as SuperGLUE, which measures the quality of the learned representation.
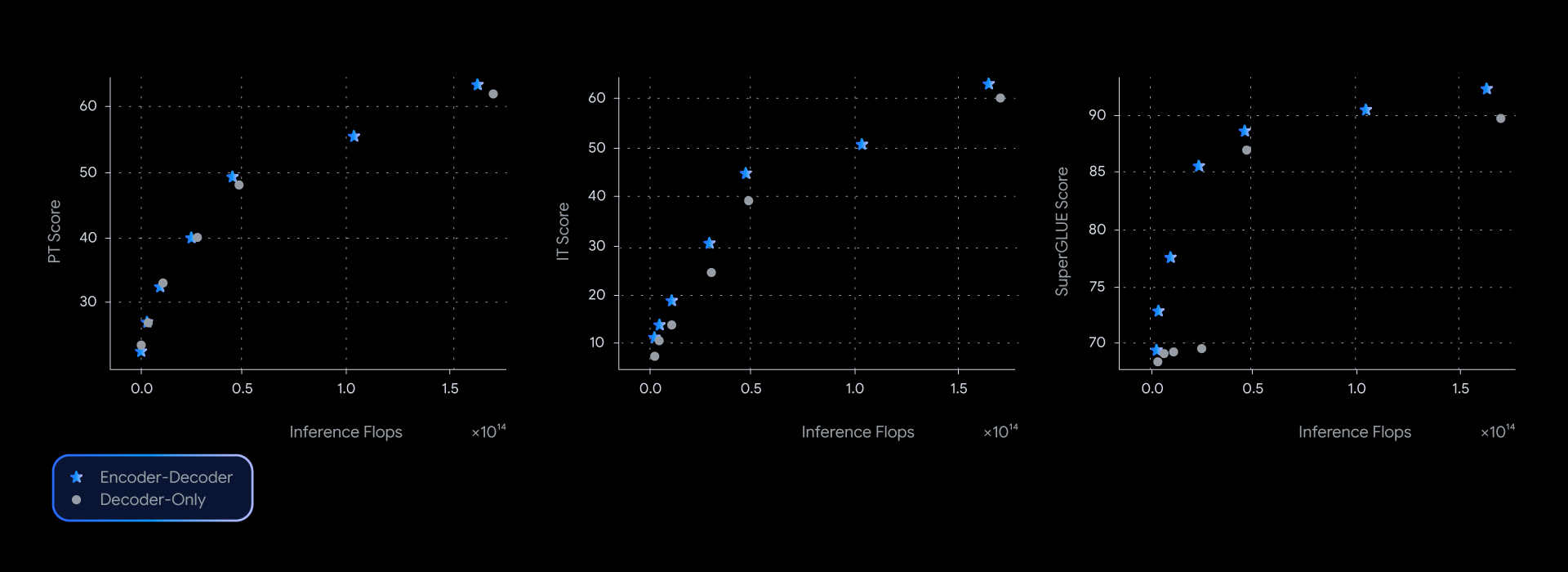
Codec models consistently offer better performance for a given level of inference computation, pushing the envelope on quality and performance across a range of benchmarks.
This performance advantage is not just theoretical; this also translates into quality and speed in the real world. By measuring real latency for GSM8K (mathematical reasoning), T5Gemma delivered a clear win. For example, the T5Gemma 9B-9B achieves higher accuracy than the Gemma 2 9B, but with similar latency. Even more impressively, the T5Gemma 9B-2B provides a significant increase in accuracy over the 2B-2B, yet its latency is almost identical to the much smaller Gemma 2 2B. Ultimately, these experiments show that encoder-decoder adaptation offers a flexible and effective way to balance inference quality and speed.
Unlocking basic and refined capabilities
Could the LLM codec have similar capabilities to decoder-only models?
Yes, T5Gemma shows promise both before and after instruction tuning.
After initial training, T5Gemma achieves impressive results on complex reasoning tasks. For example, the T5Gemma 9B-9B scores over 9 points higher in GSM8K (Mathematical Reasoning) and 4 points higher in DROP (Reading Comprehension) than the original Gemma 2 9B. This pattern shows that the encoder-decoder architecture, when initialized through adaptation, can produce a more efficient and effective base model.
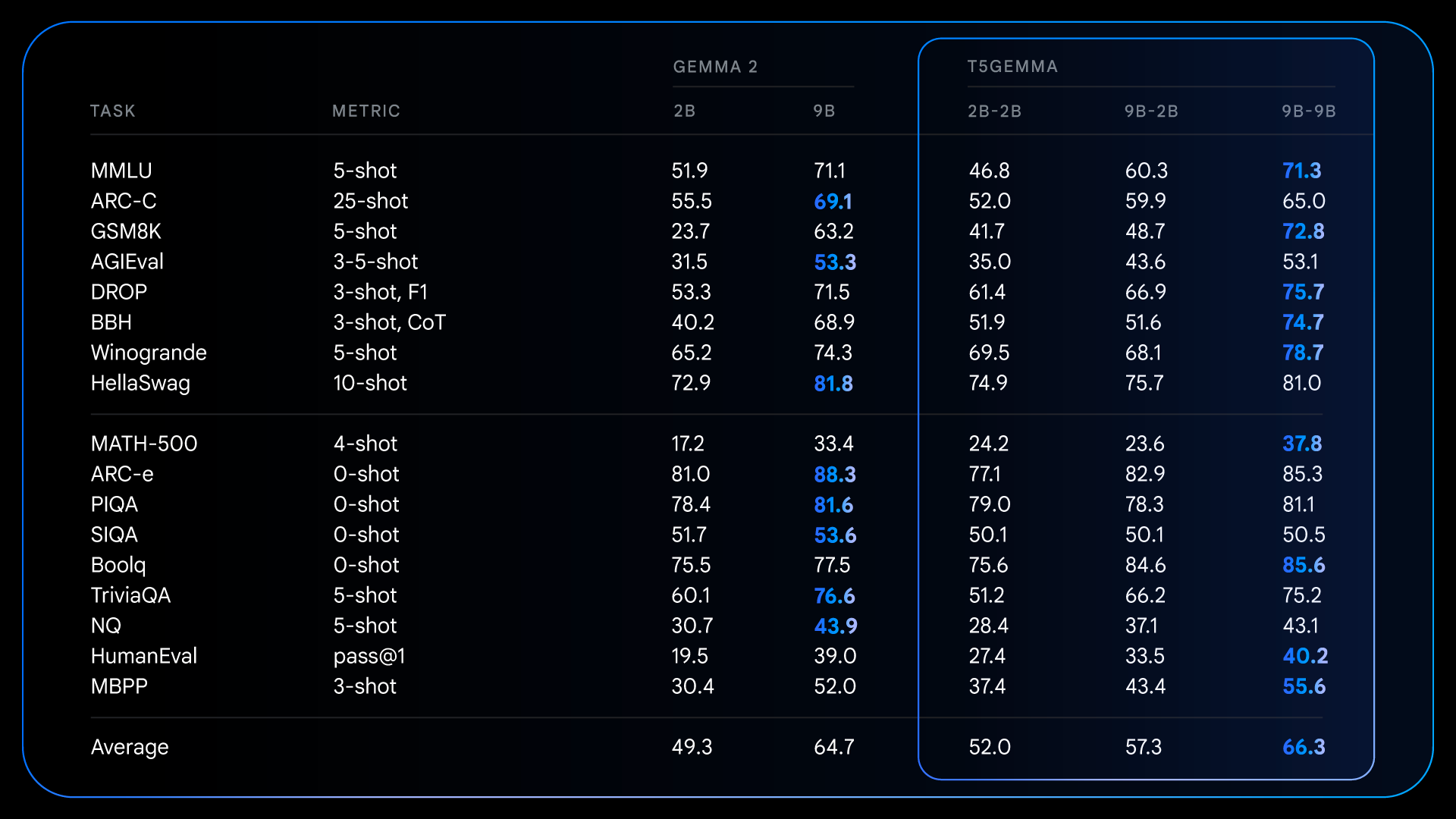
Detailed results for pre-trained models illustrating how customized models deliver significant benefits on several reasoning-intensive benchmarks compared to the decoder-only Gemma 2.
These fundamental improvements made before training set the stage for even more dramatic gains once the instructions were fine-tuned. For example, when comparing the Gemma 2 IT with the T5Gemma IT, the performance difference increases significantly in all cases. The T5Gemma 2B-2B IT sees an increase in MMLU score of almost 12 points over the Gemma 2 2B, and the GSM8K score increases from 58.0% to 70.7%. Not only does the adapted architecture potentially provide a better starting point, but it also responds more effectively to instruction tuning, ultimately leading to a much more efficient and helpful final model.
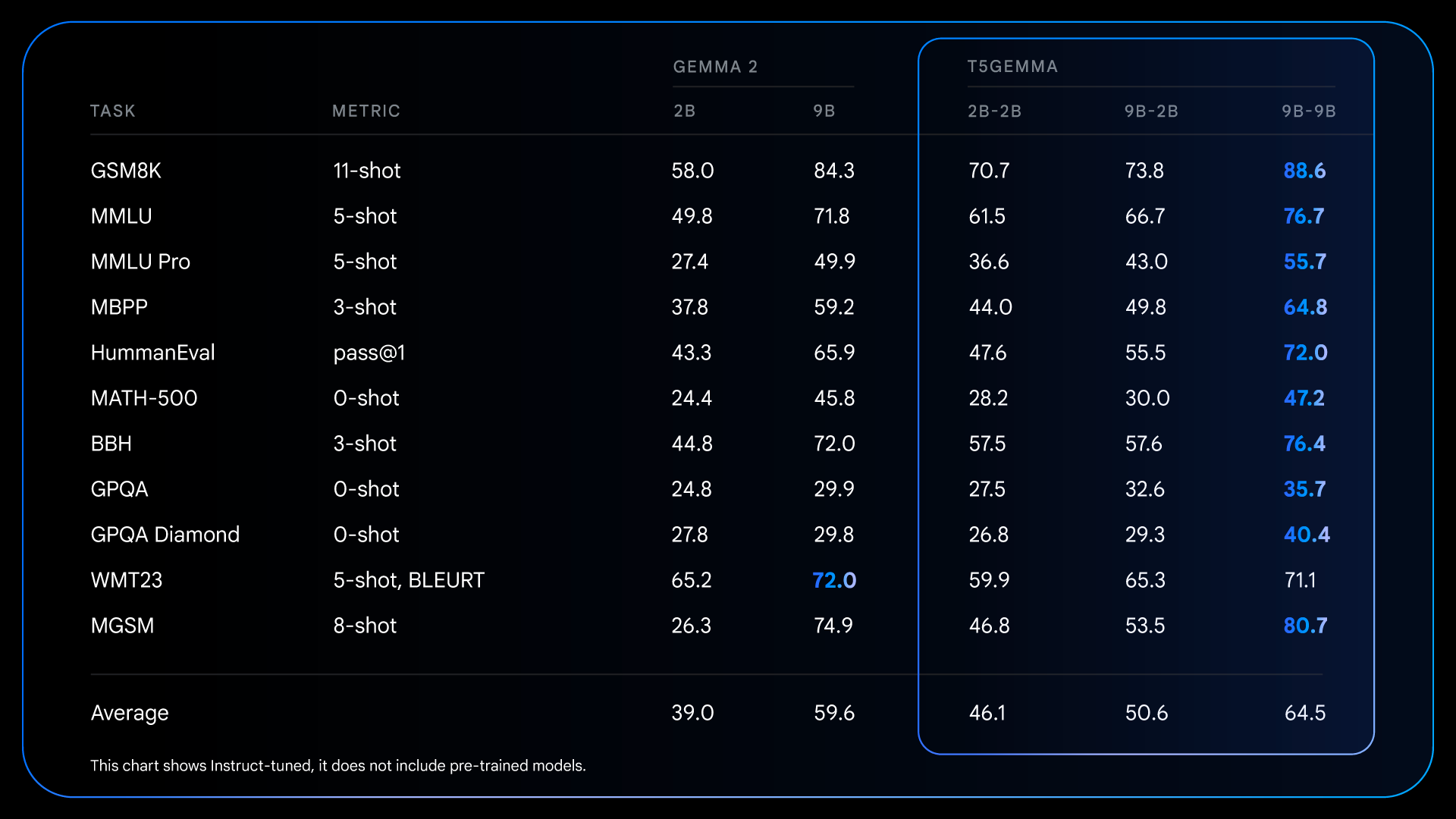
Detailed results for tuned +RLHFed models, illustrating post-training opportunities to significantly enhance the performance benefits of the encoder-decoder architecture.
Discover our models: T5Gemma checkpoint release
We are very excited to demonstrate this new method for building efficient general-purpose codec models by adapting from pre-trained decoder-only LLMs such as Gemma 2. To accelerate further research and enable the community to build on this work, we are excited to release a set of our T5Gemma checkpoints.
The edition includes:
- Multiple sizes: Checkpoints for T5 size models (Small, Base, Large and XL), Gemma 2 based models (2B and 9B), and an additional model between T5 Large and T5 XL.
- Many variants: Models pre-trained and tuned to instructions.
- Flexible configurations: A powerful and efficient 9B-2B unbalanced checkpoint for exploring encoder and decoder size trade-offs.
- Various training objectives: Models trained with PrefixLM or UL2 targets to ensure state-of-the-art generative performance or representation quality.
We hope that these checkpoints will provide a valuable resource for examining model architecture, performance, and efficiency.
First steps with T5Gemma
We can't wait to see what you build with T5Gemma. For more information please use the links below:
- As you read, you will learn more about the research behind this project paper.
- Explore the capabilities of the models or adapt them to your own applications using the tool Colab notebook.


















{kind=link}